
This is a course note of an online course I took relating to the Operating System on educative.io.
Chapter 2. Hard Disk Drives
The drive consists of a large number of read/write sectors (512-byte blocks), which are numbered from 0 to n-1on a disk with n sectors (0 to n-1 is the address space of the drive). Many file systems will read or write 4KB at a time . However, when updating the disk, a single 512-byte write is atomic (i.e., it will either complete in its entirety or won’t complete at all).
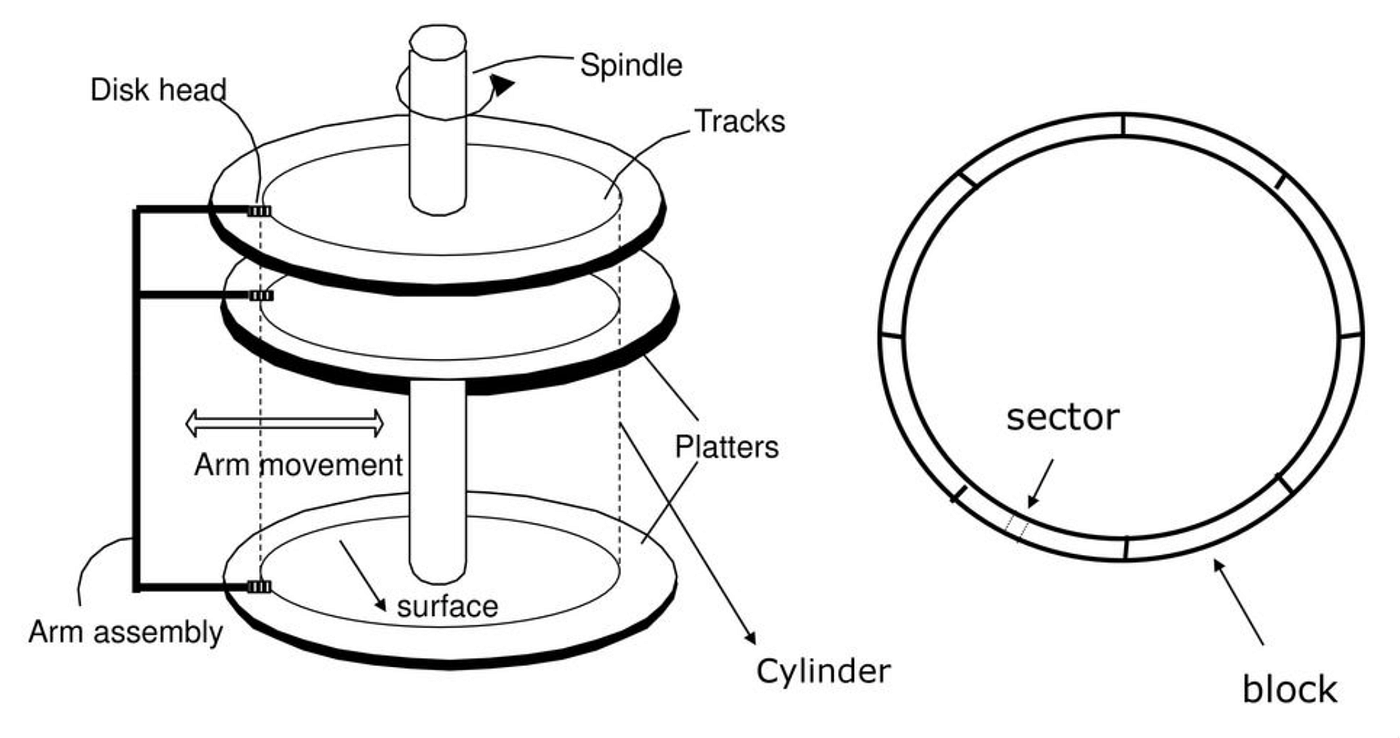
A hard disk’s performance is characterised by its access time; this is the sum of the seek time taken by the head to move to the correct track, the rotational latency while the disk rotates until the head is over the desired block, and the transmission time needed to transfer data to or from the block.

Track skew: Many drives employ some kind of track skew to make sure that sequential reads can be properly serviced even when crossing track boundaries.
Cache: cache, also called a track buffer. This cache is just small memory, usually 8 or 16 MB, which the drive can use to hold data read from or written to the disk, e.g., when reading a sector from the disk, the drive might decide to read in all of the sectors on that track and cache them in its memory.
On writes, there is two types of count:
- Write back caching (or sometimes immediate reporting): when the data in its memory,
- Write through: when the write has actually been written to disk
Disk Scheduling
SSTF(shortest seek time first ):
SSTF orders the queue of I/O requests by track and picks requests on the nearest track to complete first. However, the starvation. Imagine there were a steady stream of requests to the inner track, where the head currently is positioned. Requests to any other tracks would then be ignored completely by a pure SSTF approach.
Elevator (a.k.a. SCAN or C-SCAN) : The answer to this query is SCAN, simply moves back and forth (sweep) across the disk servicing requests in order across the tracks. Thus, if a request comes for a block on a track that has already been serviced on this sweep of the disk, it is not handled immediately, but rather queued until the next sweep. However SCAN ignore rotation and not really SJF
SPTF (shortest positioning time first ):
What it depends on here is the relative time of seeking as compared to rotation.
RAID
How can we make a large, fast, and reliable storage system? Hence, the Redundant Array of Inexpensive Disks — RAID, a technique to use multiple disks in concert to build a faster, bigger, and more reliable disk system.
At a high level, a RAID is very much a specialised computer system: it has a processor, memory, and disks. However, instead of running applications, it runs specialised software designed to operate the RAID.
Advantages of RAID
- Performance: Using multiple disks in parallel can greatly speed up I/O times.
- Capacity: Large data sets demand large disks.
- Reliability: spreading data across multiple disks makes the data vulnerable to the loss of a single disk; with some form of redundancy, RAIDs can tolerate the loss of a disk and keep operating as if nothing were wrong.
Parity
A parity bit, or check bit, is a bit added to a string of binary code. Parity bits are a simple form of error detecting code. Parity bits are generally applied to the smallest units of a communication protocol, typically 8-bit octets (bytes), although they can also be applied separately to an entire message string of bits.
A parity drive is a hard drive used in a RAID array to provide fault tolerance. For example, RAID 3 uses a parity drive to create a system that is both fault tolerant and, because of data striping, fast.Basically, a single data bit is added to the end of a data block to ensure the number of bits in the message is either odd or even.
RAID Level 0: Striping
RAID 0 splits (“stripes”) data evenly across two or more disks, without parity information, redundancy, or fault tolerance. Since RAID 0 provides no fault tolerance or redundancy, the failure of one drive will cause the entire array to fail; the failure will result in total data loss. This configuration is typically implemented having speed as the intended goal.
Data striping is the technique of segmenting logically sequential data, such as a file, so that consecutive segments are stored on different physical storage devices.

Striping is useful when a processing device requests data more quickly than a single storage device can provide it. By spreading segments across multiple devices which can be accessed concurrently, total data throughput is increased. It is also a useful method for balancing I/O load across an array of disks.
A RAID 0 array of n drives provides data read and write transfer rates up to n times as high as the individual drive rates, but with no data redundancy. As a result, RAID 0 is primarily used in applications that require high performance and are able to tolerate lower reliability.
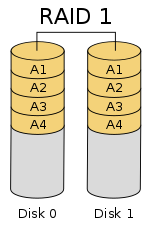
RAID 1 Mirroring
RAID 1 consists of an exact copy (or mirror) of a set of data on two or more disks; a classic RAID 1 mirrored pair contains two disks. This layout is useful when read performance or reliability is more important than write performance or the resulting data storage capacity. The array will continue to operate so long as at least one member drive is operational.
Any read request can be serviced and handled by any drive in the array; thus, depending on the nature of I/O load, random read performance of a RAID 1 array may equal up to the sum of each member’s performance, while the write performance remains at the level of a single disk.
RAID 4
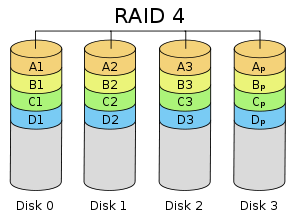
RAID 4 consists of block-level striping with a dedicated parity disk. As a result of its layout, RAID 4 provides good performance of random reads, while the performance of random writes is low due to the need to write all parity data to a single disk, at least as long as the filesystem is not RAID 4-aware and compensates for that.
For each stripe of data, we have added a single parity block that stores the redundant information for that stripe of blocks. For example, parity block P3 has redundant information that it calculated from blocks 1, 2, and 0.
To compute parity, we use function XOR does the trick quite nicely. For a given set of bits, the XOR of all of those bits returns a 0 if there are an even number of 1’s in the bits, and a 1 if there are an odd number of 1’s. For example:
In diagram 1, a read request for block A1 would be serviced by disk 0. A simultaneous read request for block B1 would have to wait, but a read request for B2 could be serviced concurrently by disk 1.
Interface and RAID Internals
When a file system issues a logical I/O request to the RAID, the RAID must calculate which disk to use, and then issue one or more physical I/Os to do so.
Internally, however, RAIDs are fairly complex, consisting of:
- A microcontroller that runs firmware to direct the operation of the RAID.
- Volatile memory such as DRAM to buffer data blocks as they are read and written.
- In some cases, non-volatile memory to buffer writes safely and perhaps even specialised logic to perform parity calculations.
That’s so much of it!
Happy Reading!
